The Data Warehouse (Legacy)
This article refers to Relevant’s old data warehouse structure, which was changed in spring and summer 2023. For documentation of the new structure, which contains a single unified database, see here.
Relevant provides full access to your health center’s data. The data warehouse consists of two databases: the s taging**database** and the analytics(or ”Relevant”) **database**.
The diagram below shows how the data flows from your EHR (and potentially other data sources) into Relevant’s data warehouse, and finally into the Relevant web app itself. Typically, this entire process (sometimes referred to as extract-transform-load, or ETL) runs nightly.
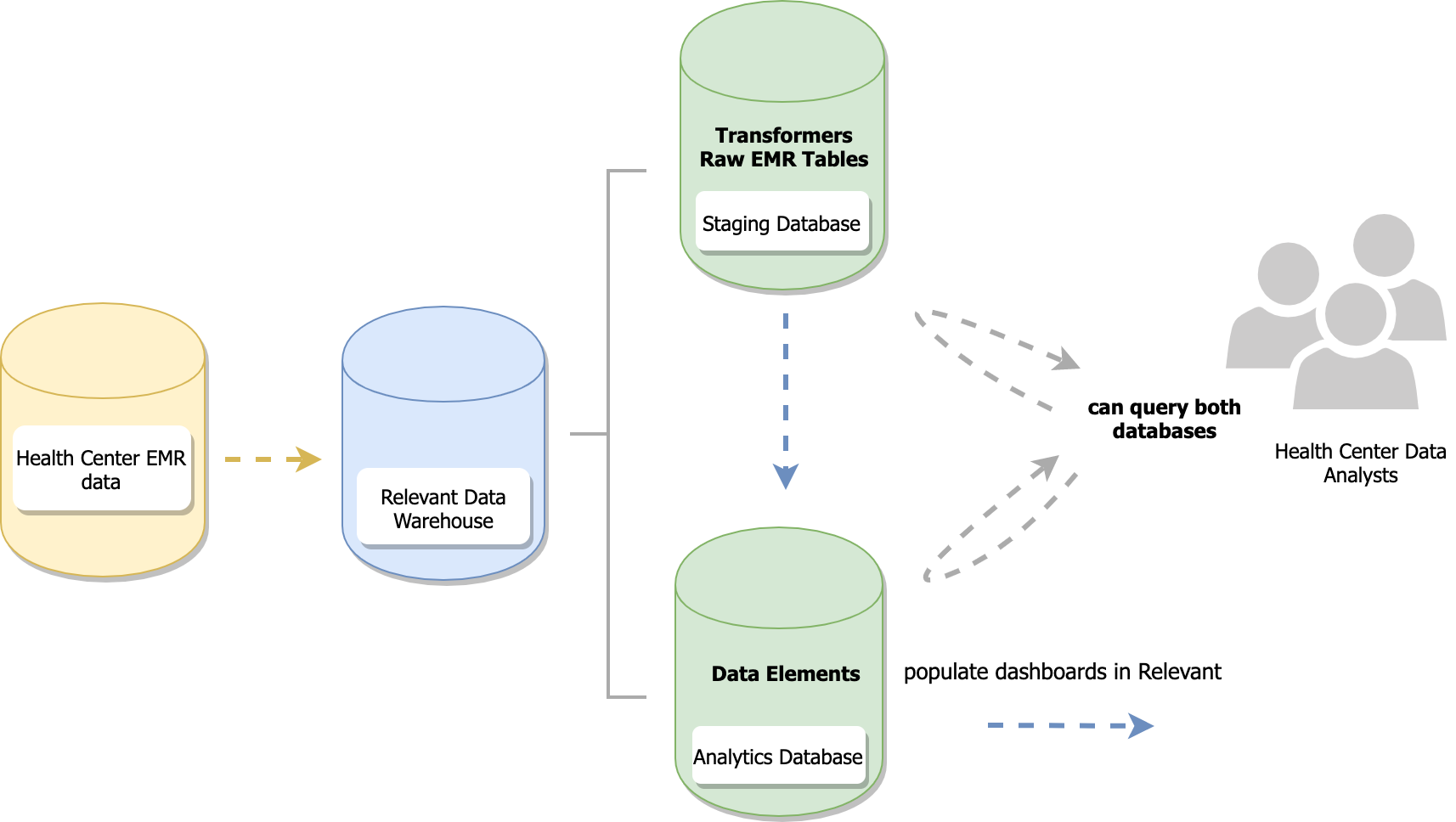
The staging database supports data cleanup and transformation. It consists of raw data from your EHR and/or other sources (e.g., managed care payer data, electronic dental records data), as well as any cleaned or transformed tables that help with data cleanup and later analysis. Data analysts at your health center can add any transformed tables that they need. Because of this customizability, the structure of your staging database can be unique.
The a nalytics database populates Relevant’s screens and keeps the app running. Health centers have control of the mapping of data elements into the analytics database, and later query it as a source of truth. However, because it is Relevant’s standard data model, health centers cannot create new tables or alter table schemas in the analytics database.
This also means, that unlike the fully customizable staging database, every Relevant user has the same tables and columns in their analytics database. That means you can do cool things, like share report definitions, or compare data across a health center-controlled network, even though individual health centers may use different EHRs.
For more information about customizing the data warehouse, see the Data Pipeline section.